
CADERIGE/CADIXE
CADIXE in a Nutshell: Why and What !
The annotation task
More and more, we need to automatically process cultural, technical, or scientifical documents. However, as the natural language is not directly understandable by the computers, a preliminary task consists to enlighten the semantic of the textual documents by inserting within documents a specific set of keywords. The XML language is well-suited to do this annotation task. In such process, the user inserts progressively some XML tags described through an external DTD (grammar). For instance in an historical domain, you could have the following annotation :
| • Initial sentence |
| Henry was born in 1491 and becames king at the age of 18 |
| • XML tagged sentence |
| <king>Henry</king> was <birth date =1491> born in 1491 </birth> and <crown kingdom=england age=18> becames king at the age of 18 </crown> |
A specific editor
However, it is easy to see that the insertion of XML tags is somewhat heavy if you just work with a classical text editor. Therefore, there exists a lot of implementation of XML editors but most of them are oriented toward the creation or the modification of XML documents and are rather poorly adapted to this annotation task. So, the CADIXE editor has been developed to fulfil this needs and to allow the user :
- To insert tags with very few constraints on the insertion order
- To visualize documents not as a tree or an XML document, but just as a text
- To eases the collaboration between several annotators
- To avoid a long and complex learning curve
The first requirement is of course crucial since during the annotation task the user interprets “in real time” the meaning of the document. So it is not possible to force him/her to enter the tags in the way they are organized in the DTD, because the first element identified by the user is not always (never in fact) the root of the DTD. So, an annotation editor must provide some freedom to the annotator in the way he/she inserts the information.
The interface of CADIXE editor we developed in the Caderige project is mainly composed of four main parts. The text zone where the user sees the text he/she want to annotate, the XML code currently generated and the list of the tags that can are allowed in the current contex and finally the attributes zone allowing to enter or to modify the values associated to the current tag (i.e. the tag in which the text cursor has been moved).
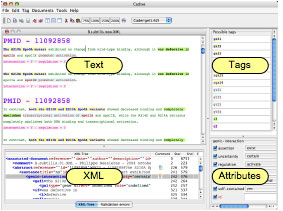
Thus, the tagging process is simple : first the user highlights with the cursor the part of the text to annotate. The tags list shows all the relevant tags. The user selects the tag he/she wants to apply and then enters the values in the attributes editor. There is also a mode in which the editor forced the user to enter the values of the attributes. This mode is relevant when the user is not familiar with the DTD. Moreover, it is possible to associate to each tag a “comment” to explain the annotation choices to the other member of a project.
Finally, a “style” is associated to each tag in order to express the way this tag is displayed in the document. Several style sheets (based on the CSS format) can be loaded in a document to allow different “point of view”. For instance, in a biological domain, an annotated sentence could look like this one: each color corresponding to a specific information :
![]()
The CADIXE editor has been implemented in JAVA 1.42 and it can be used on the following platforms : Windows, Linux, MacOs X. It is used in our project but also at the SIB (Swiss Institute of Bioinformatics) with another DTD, in the frame of the European project “BioMint”. The software can be (freely) obtained by any researcher, which is involved in a document annotation task, please contact us !